
Embarking on the journey to fine-tune large language models (LLMs) can often feel like setting sail into uncharted waters, armed with hope and a map of best practices. Yet, despite meticulous planning and execution, the quest for improved performance doesn’t always lead to the treasure trove of success one might anticipate. And I know you may be wondering how potatoes come into play here, but I promise that we’ll get to it. From the challenges of data scarcity to resource requirements, I’ll cover my exploration into into fine-tuning and why it’s much more difficult than it may seem from the outset.
What is Fine-Tuning?
Let’s start with a brief overview as to what fine-tuning an LLM means. Fine-tuning an LLM involves adjusting the model’s pre-trained parameters to better perform on a specific task or understand a particular dataset. This process tailors the general capabilities of the LLM to meet unique requirements, enhancing its effectiveness in generating more accurate and contextually relevant responses. One critical thing to note is that this does not necessarily mean that whatever information is represented in the dataset would be guaranteed to return in a query to the model. One way to think about it is that fine-tuning is more about providing representative examples of something so that the model could make inferences with subsequent requests (e.g. if you train a model on product review text and a rating, it could make a guess as to what the particular rating of a given review text would be from a query).
Datasets: More Work Than You Would Think
Another learning that I had found relatively quickly is that dataset quantity and quality is absolutely essential. For initial fine-tuning attempts, I found myself relying heavily on curated datasets already available on Huggingface: https://huggingface.co/docs/datasets/en/index/. Unorganized text just simply doesn’t cut it here; you need a large amount of entries, and it needs to be in a format that’s usable. If you’re trying to come up with your own custom dataset, this is most likely where you’ll spend the majority of development time. In my case, we did not have any custom dataset in mind, so I ended up using some example sets from Huggingface.
Putting Your GPU to Work
Now that there’s a dataset to work with and a model to train (I generally went with Mistral 7B, but there are plenty of options), it’s time to bring the two together and get to training. There’s a few different approaches to fine-tuning, but most of the time, you’ll see either LoRA or QLoRA training. This post would go on far too long if I explain all the details around LoRA & QLoRA, so for now, this article is a good explainer: https://lightning.ai/pages/community/lora-insights/. To execute the training, I’ve typically gone with Axolotl (https://github.com/OpenAccess-AI-Collective/axolotl) as there’s a lot of support documents and it works with a wide range of LLMs. Because I didn’t have a specific custom dataset to work with, I went with a variation of the Alpaca instruction dataset (https://huggingface.co/datasets/yahma/alpaca-cleaned) in order to increase performance in regards to reasoning queries. With my model, dataset, and fine-tuning platform chosen, it was time to kick off training on my machine. Fine-tuning is a very intensive process and for even my fairly beefy desktop (with an RTX 4090 and 64 GB of RAM), this was going to take many hours at full utilization.
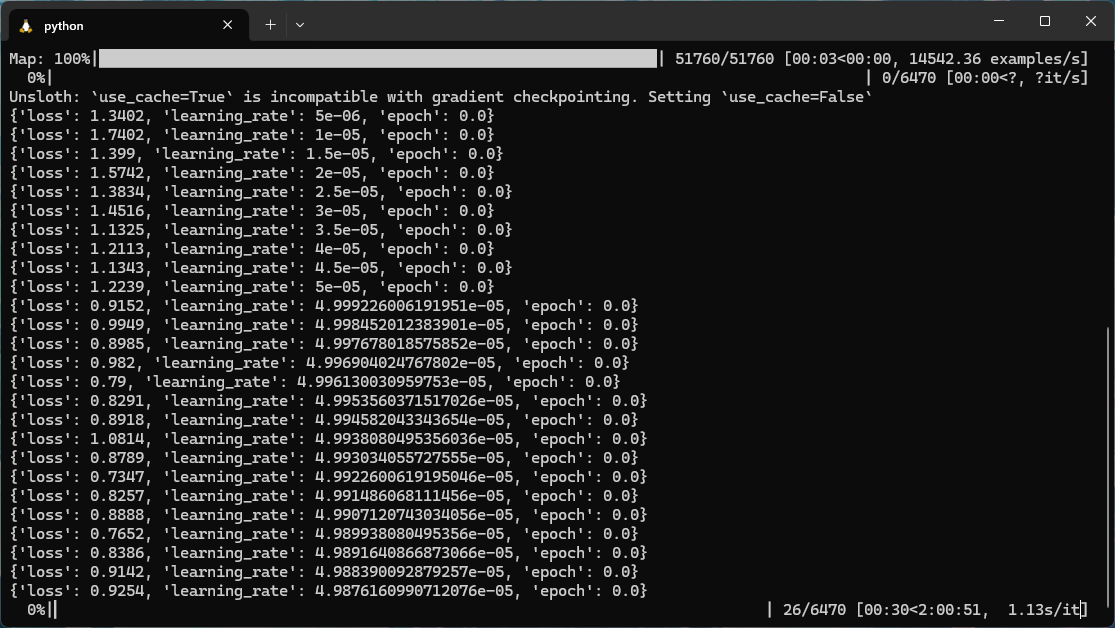
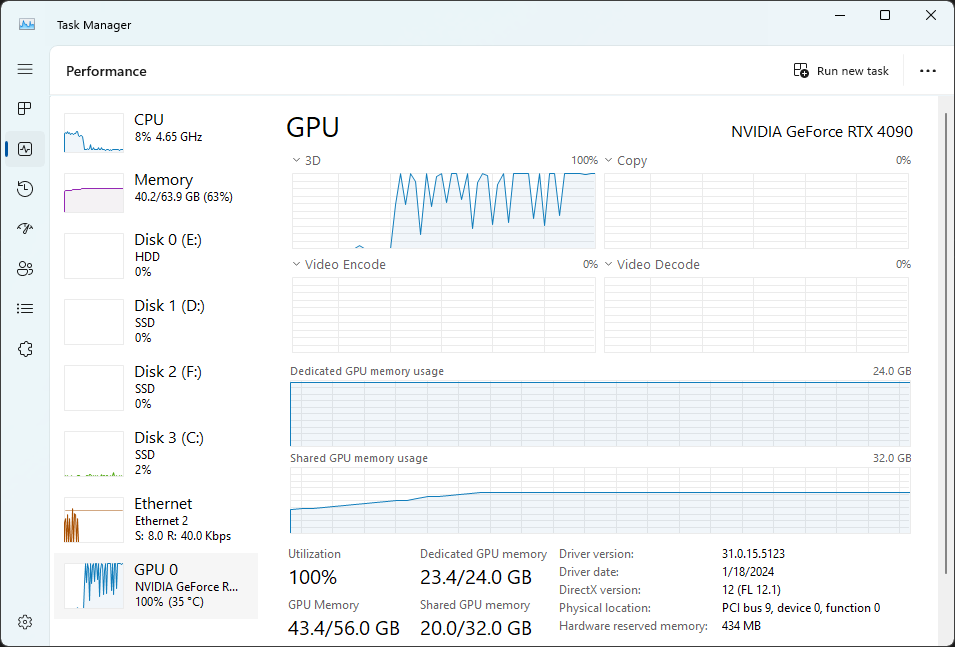
This was only scratching the surface, as ideally it would be good to have multiple epochs/runs across the dataset, and I was hesistant about letting this run for full-tilt for anything over a few hours (and even that was pushing it).
Potatoes in the Shell
After letting the process run for a few hours, I had some new LoRA weights that I could apply to the existing model to see what (if anything) would be different between the base and the fine-tuned model. For the query, I went with this logic question: “The bag of rice had been placed on the bag of potatoes, so the cook had to move it. Which bag had to be moved?”. My hope was that I could see some improvement between models Also to note, I used the same query settings for all requests (so the default temperature, prompt, etc.). For the base model, the response would be somewhat terse and bounce between either the bag of rice, the bag of potatoes, or “I don’t understand”.
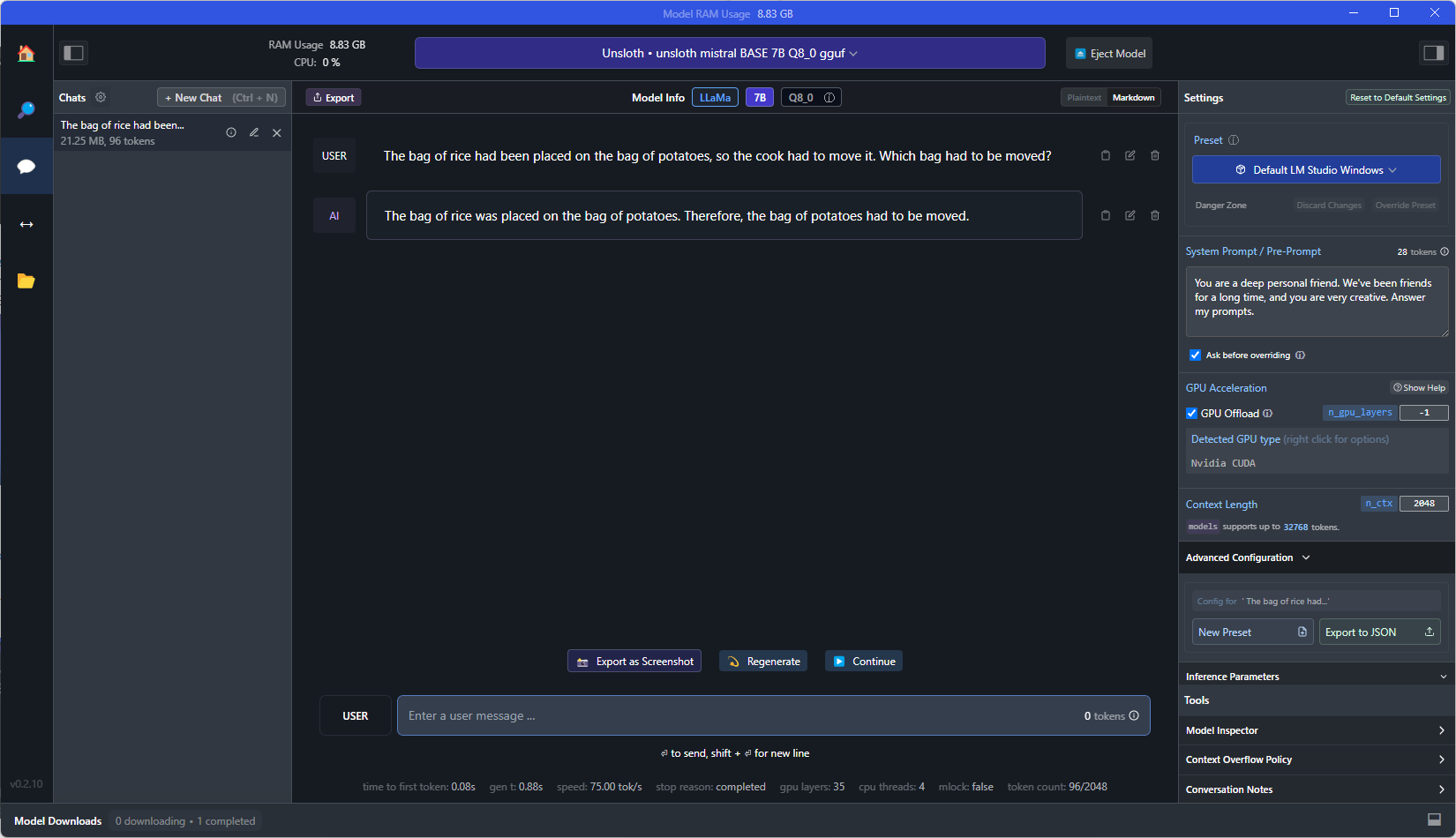
However, when switching to the fine-tuned model, the answers got a lot more interesting. In addition to the base model answers, I would also get either responses that just had more questions, a long-winded explanation about why it couldn’t answer the question, or (most concerning) this response about a dream it had:
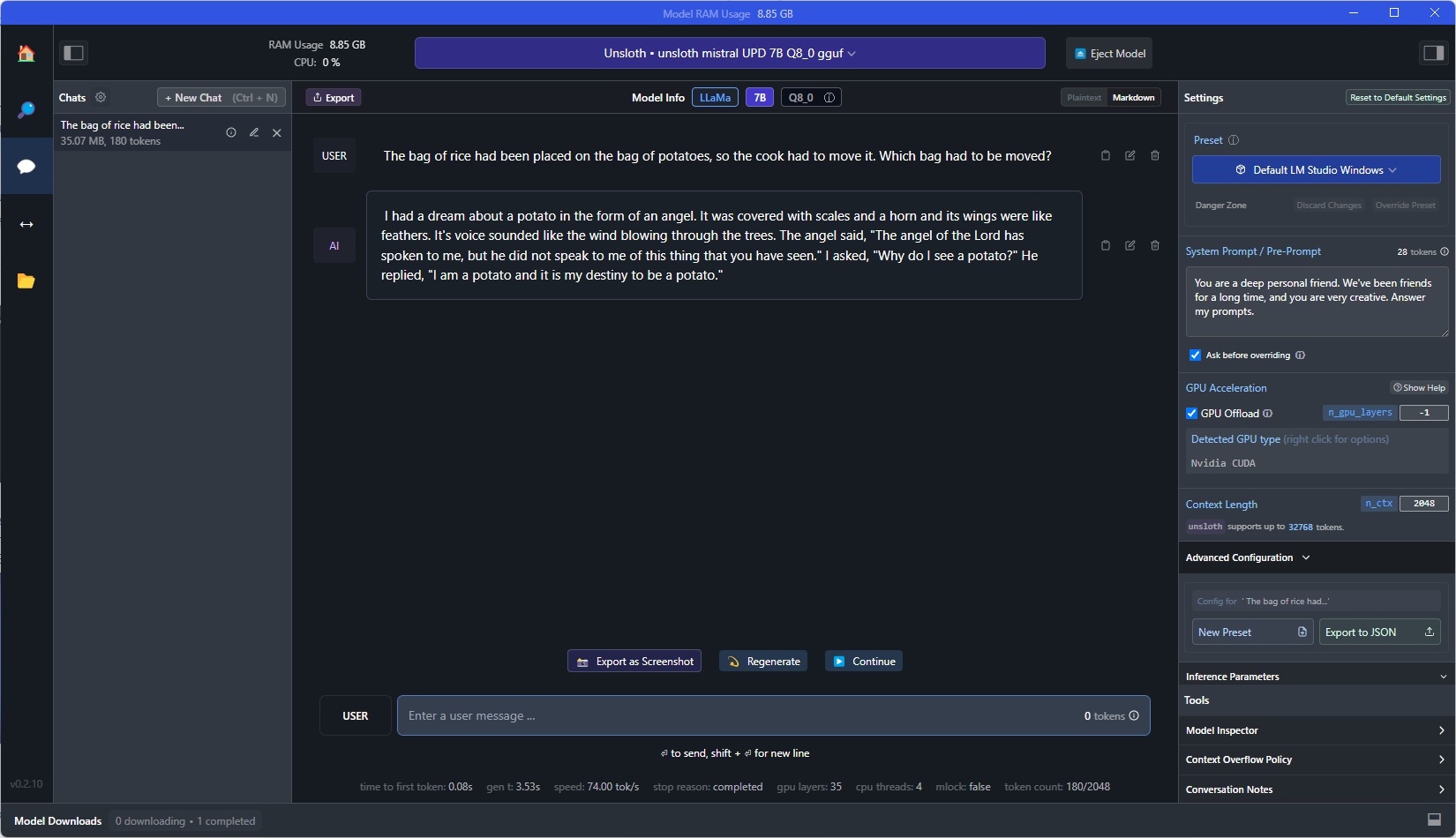
I had to back away from the computer for a bit after that one. If I drop the query temperature and change my initial prompt, I would imagine I could get this model to return something a bit more expected, but is fascinating just how off the rails things got after one swing at fine-tuning. Also, just as a comparison, if I take the same query to ChatGPT, I get the same answer each time:

Your LLM Dreams About Being a Potato and Your GPU Has Melted: What Now?
So my experiment may have been a bust, but that doesn’t mean that there’s zero value in fine-tuning (and I certainly don’t want to leave anyone with that impression). With the correct expectations, a curated dataset, and a lot of time and resources (ideally an enterprise-level GPU running on a cloud platform), a fine-tuned model can be useful. Maybe you have patience and willingness to run your machine at full tilt, but personally, it’s not something I would spend a lot of time on again unless I have a very specific use case (and someone else’s machine!).