This was originally planed as a post about S3 Table Buckets, announced at re:Invent 2024 (and in my opinion as a builder of data pipelines, one of the top announcements of that conference). However, after a couple of days exploring, including watching the re:Invent introduction video, I realized that S3 Tables weren’t quite ready for primetime — at least not for the types of data pipelines that I build. The main reason is that the only way to create and populate an S3 Table is via a Spark job. I prefer streaming pipelines, typically built around Amazon Data Firehose (formerly known as Kinesis Firehose).
Which is a shame, because the automated table optimization features of S3 Tables seem targeted directly at streaming pipelines, solving the problem of small files in a data lake. But fortunately, you don’t need to use S3 Tables to get access to this capability: in November AWS announced that Glue could perform the same optimizations on Iceberg tables stored in a normal S3 bucket.
In this post I look at these capabilities using my favorite source of small files, CloudTrail. I develop a data pipeline using Amazon Data Firehose, writing to an Iceberg table stored in S3. I compare the performance of that Iceberg table to a Parquet table fed by the same data stream, as well as to a Parquet table with the same data that I built as described in this blog post.
You will find example CloudFormation templates here.
What is Iceberg?
Apache Iceberg isn’t a file format per se. Instead, it’s a framework that stores data in Parquet (or ORC) files, with separate metadata files that specify which data files belong to the current dataset (picture here). This enables the following features:
- Each update is a snapshot of the data. This provides read isolation: queries do not see data that was added after they were started. It also allows time travel queries, in which you query the dataset as-of a particular snapshot.
- Data files can be combined (compacted): a new snapshot references the compacted files, while older snapshot(s) reference the uncompacted files. This improves query performance, because there are fewer files to read and Parquet is more efficient with larger files.
- Partitions are “hidden”: the people writing queries do not need to know about the partitioning scheme to benefit from it. Moreover, the partition scheme can change if needed, without requiring existing queries to be rewritten.
- Iceberg supports deletes as well as inserts (and updates, as a delete combined with an insert). This means that you can replicate changing data sources in your data lake; it’s not just an append-only repository.
In the past, I haven’t paid much attention to Iceberg: other than support for deletes and updaes it didn’t appear to offer much benefit over plain Parquet data files – in fact, because of the layer of indirection through (small) metadata files, it was arguably worse. And while compaction was intriguing, the process was quite involved (see this AWS blog post as an example).
Creating an Iceberg Table
You can create an Iceberg table using Athena, the Glue Data Catalog, Spark, or an infrastructure-as-code tool such as CloudFormation). If you use Athena, read the AWS documentation first; especially for the CREATE TABLE AS statement: Iceberg tables use different parameters than Parquet tables.
If you use CloudFormation (or the Glue API in general), the resource definition looks similar to a traditional table, but omits format and SerDe configuration. You must also add an OpenTableFormatInput property, which simply tells CloudFormation that you’re creating an Iceberg table (I assume that this property may be use for other purposes in the future). And you can’t configure partitioning when creating the table.
When stored on S3, an Iceberg table has two sub-folders: data/ and metadata/. The former holds Parquet data files; the latter a mix of JSON and AVRO files identifying the data files that belong to each snapshot (along with other information). The initial metadata files are written when the table is created; each update adds additional files, and the Glue table definition points to the latest metadata.
Partitioning
Traditional data lakes specify partitions as part of the file prefix. For example, a date-partitioned table might have filenames like s3://com-example-data/my_table/2024/10/17/data00001.parquet. You can define your Glue table to include those portions of the path as columns, and then reduce the amount of data a query scans by adding predicates on those columns. Effective partitioning can be a dark art, and with traditional data lake tables, changes to the partitioning scheme typically require rewriting partition-aware queries.
With Iceberg, partitions are defined as a transformation of a table column. For example, the year, month, and day of the event_time field. Queries that use the underlying column will benefit from the partition, without using additional predicates. And they don’t have to be rewritten if you change to a different scheme (for example, adding hour to the partition scheme for extremely high-volume data). Behind the scenes, the metadata identifies which partition values are stored in which data files.
One important caveat: as-of this writing, you can only specify partitions when you create an Iceberg table, and only when you use Athena DDL to create the table. You can’t specify partitions using CloudFormation or the Glue API. As a result, I have largely ignored partitions in this post.
Truncating Data
When developing a traditional table, I often iterate on the code that populates that table. Between iterations, I delete the files from S3 to “truncate” the table. This won’t work with Iceberg, because the metadata will no longer be valid. Instead, you’ll need to either drop and recreate the table definition (including deleting the files on S3), or running a DELETE statement.
I don’t recommend using DELETE, because it leaves all existing data files in place – in fact, it will add a file identifying the deleted rows. And unless you have compaction enabled, queries will continue to read the old data (and then promptly ignore it).
Configuring Table Optimizations
Glue provides three optimizations:
- Compaction: combining data files to minimize the number of files read.
- Snapshot cleanup: deleting metadata files for snapshots that are past a specified age. This is particularly useful for streaming sources, which create a new snapshot with each batch of data processed.
- Orphan file cleanup: deleting data files that are not referenced by any snapshots. This works hand-in-hand with snapshot cleanup.
You can enable or disable any or all of these in the Console. And while I normally push as much work onto CloudFormation as possible, as of this writing it only supports the compaction optimization. So I create the table in CloudFormation, but then move to the Console to enable optimization.
The default table optimization settings are to retain snapshots for five days, to retain at least one historical snapshot, and to retain orphan files for three days. For a stable, append-only file format like CloudTrail, these are arguably overkill; you could reduce the snapshot retention and orphan file deletion to 1 day.
However, I think that the defaults are too low for many business use cases, especially those that involve streaming data. For Firehose, each batch of data becomes a new snapshot, and these might happen every 10-15 minutes. If there’s a problem, you might not discover it until dozens of snapshots have been created (and recovering from such a problem will potentially be a long process).
Another reason to keep additional snapshots is to support “time travel” queries, in which you query the state of the dataset as-of a particular point in time or snapshot version. While that may not be high on your list for a production table, I think it’s likely during development (there have been many times that I wished for the capability).
Firehose Architecture and Configuration
With the table configuration out of the way, we can set up a Firehose to populate it. For this example I’m using a standard Firehose architecture: records are written to a Kinesis Data Stream, then processed by the Firehose and written to S3.
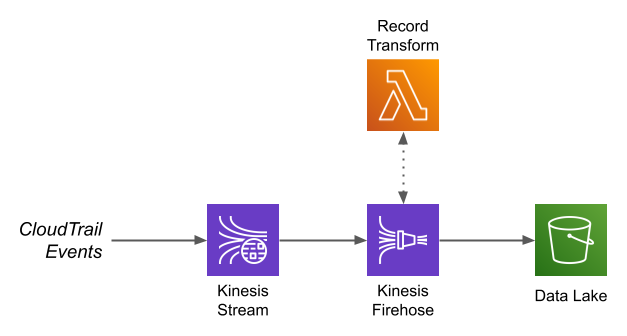
Not shown here is how the records get onto the Kinesis stream. This is handled by a Lambda, triggered by CloudTrail writing a file to S3. This Lambda extracts the individual CloudTrail records (because Firehose can’t do 1:M transformations), stringifies any fields that contain nested JSON (because CloudTrail events are too complex to fully represent with a Glue table definition), and writes the records to Kinesis. You can find it here.
I always prefer a Kinesis Stream as the starting point for a data pipeline, rather than writing records directly to Firehose. Partly, this is historical: in the early days, Firehose could not scale as easily as a stream. However, the bigger reason is that a stream can serve multiple consumers. In the case of this example, I use a single data stream as the input to two firehoses.
Firehose execution role
FIrehose assumes an IAM role to do its work. The permissions for reading the Kinesis Data Stream, logging, and writing to S3 are common between Parquet and Iceberg tables. However, the Iceberg Firehose requires additional permissions to read and update the Glue data catalog at runtime. Refer to the page “Controlling access with Amazon Data Firehose” for detailed permission settings (or just look at the example’s CloudFormation templates).
Transformation from JSON to Parquet/Iceberg
Firehose can read JSON data and convert it to Parquet or Iceberg. In both cases, it uses an existing Glue table definition to control the conversion. However, there are significant differences in how you configure the Firehose for the two output formats.
For Parquet, a single Firehose can populate a single table; you must provide the name of that table when creating the Firehose. For Iceberg, Firehose can write to multiple tables, using the contents of the events themselves to identify the destination table. This is great for processing streams that contain multiple record types, such as those produced by the AWS Database Migration Service. However, you must also configure this feature even if you only have a single record type in your stream.
There are two configuration settings. The first, which appears in the Console as “Inline parsing for routing information,” has three JQ expressions, to extract the destination database name, table name, and update type. These expressions can dig into the source record, or they can be literal strings (which must be entered with quotes; for example, "default"). The example uses literals, since it’s writing a single destination table.
The second configuration component appears in the Console as “Unique key configuration.” It’s a JSON list of objects that identify database, table, and the field(s) that comprise the table’s primary key. The Console describes it as optional, and that’s true when you create the Firehose in the console, but CloudFormation fails if you leave it out of your template. It’s also required if you perform updates or deletes (which my example does; see below).
The interaction between these two configuration items is not obvious. I have created Firehoses in the Console by specifying one and not the other, and they’ve worked without a problem. As I mentioned, you must specify the second when creating the Firehose with CloudFormation. And if you do need to route different records to different tables, then you need the first.
For Iceberg, input field names are case-sensitive
Glue table definitions store column names in lowercase; this happens even if you provide mixed-case names to the CreateTable API call. However, JSON data typically uses camelCased identifiers. This isn’t a problem when you’re writing Parquet output: Firehose (more correctly, the OpenXJsonSerDe it uses to read source fields) lowercases the identifier to match the table. It’s ugly – recipientAccountId becomes recipientaccountid – but it works.
With Iceberg output, however, this doesn’t happen. If your source data has mixed-case identifiers, those fields won’t match the lowercased columns in the table definition, and they’ll be ignored. In the case of CloudTrail source data, the only field that matches is resources; everything else is written as null.
To solve this, you must use a record transformation Lambda. The simplest such Lambda lowercases the top-level identifiers in each record, so that they’ll match the table definition. This is what I do in my example, for consistency with the Parquet version. However, in the real world I would convert the mixed-case identifiers in the source data into snake_case identifiers (along with a similar conversion in the table definition) to make them more readable.
Iceberg supports delete and update as well as insert
A traditional Firehose, writing Parquet, is append-only: each record that it processes becomes a row in the destination table. Iceberg, by comparison, allows you to specify that a source record updates or deletes an existing record in the table. This means that you can feed a change-data-capture stream into your Firehose, to replicate your line-of-business data in your data lake. It also means that you can eliminate duplicate records from your data.
When developing this post, I learned that CloudTrail sometimes writes duplicate data to S3. It’s not often: in one month’s data, over 82,000 files, I discovered 21 that were duplicates. And for CloudTrail, it’s perhaps not that important if your counts are off a bit. But for some use cases, duplicate rows can call your entire data lake into question.
The solution to this situation is to change the “routing information” action to "update" from "insert", and to configure the “unique key configuration” with the event iD. This causes Firehose to generate two files per batch: one is the new data, and one is the list of IDs in the new data, used as an “equality delete.” The rules of Iceberg query planning say that equality deletes are applied to any data rows from earlier snapshots, effectively turning the “update” operation into an “upsert”.
This will, of course, reduce performance somewhat, because Athena has to combine the files. However, if you have compaction enabled, the compacted file only contains the newly inserted rows.
Performance
So what’s the bottom line? To test the performance of Iceberg tables, I configured two Firehoses: one produces Parquet output and one produces Iceberg. I then streamed a year’s worth of our CloudTrail data – 5,459,241 event records – into the Kinesis Data Stream that fed those Firehoses. For comparison, I also created monthly-aggregated Parquet files as described here, and I used Athena to create an Iceberg table partitioned by month.
For the Iceberg table populated by Firehose, I enabled all optimizations and waited 24 hours before running the queries.
For query times, I ran the each query once, and recorded the time and amount of data scanned. This “first run” time is usually longer than subsequnt runs, as Athena isn’t able to use a cached query plan (or cached data files), but in practice it was not large enough to be signficant.
Data Size
This table shows the dramatic difference that compaction provides for tables populated by Firehose. In my opinion, the biggest problem with using Firehose to populate a data lake is that it typically produces a lot of small files. This happens because it batches source records by time and as well as size: if the timer expires before the desired file size is reached, Firehose writes the file anyway. This is great for providing near-real-time data, not so great in producing optimal file sizes. For this example I used a five minute batch timeout; the maximum is fifteen.
| Number of Files | Average File Size (MiB) | Total File Size (MiB) | |
|---|---|---|---|
| Parquet, Monthly Aggregation | 27 | 81 | 2,186 |
| Parquet, Firehose | 1,942 | 1+ | 2,170 |
| Iceberg, Firehose | 15 | 98 | 1,434 |
| Iceberg, Partitioned | 13 | 108 | 1,401 |
One statistic that isn’t captured in this table: of the 15 data files for Firehose Iceberg, 12 of them averaged 500 KiB in size, while the other three averaged 500 MiB. I would have expected the compaction algorithm to try for a more equal size distribution.
Query 1: count of events (total and distinct)
This query has to touch every file in the dataset, although it only needs to examine one column from each file.
SELECT count(*), count(distinct eventid) FROM "default"."firehose_iceberg";
| Time (sec) | Data Scanned | |
|---|---|---|
| Parquet, Monthly Aggregation | 1.321 | 189.54 MB |
| Parquet, Firehose | 2.439 | 189.04 MB |
| Iceberg, Firehose | 2.963 | 107.08 MB |
| Iceberg, Partitioned | 3.015 | 108.84 MB |
I wasn’t surprised that the monthly aggregation took much less time than the Firehose version: that’s a simple matter of scanning fewer files. I was surprised that Iceberg took longer, and suspect that it might have suffered from not enough parallelism.
I was also surprised that Iceberg scanned significantly less data. Perhaps this is caused by a difference between the compression algorithms (ZStd for Iceberg, Snappy for Parquet)?
Query 2: count of events by event name and month
This query also has to touch every file, but now it has to look at two column in the file.
SELECT eventname, count(distinct eventid) FROM "default"."firehose_iceberg" GROUP BY 1 ORDER BY 2 DESC limit 20;
| Time (sec) | Data Scanned | |
|---|---|---|
| Parquet, Monthly Aggregation | 1.642 | 193.10 MB |
| Parquet, Firehose | 2.434 | 197.78 MB |
| Iceberg, Firehose | 2.695 | 111.57 MB |
| Iceberg, Partitioned | 3.210 | 113.02 MB |
The difference in timings between this query and the previous one are, I think, normal variance given that the amount of data scanned is about the same.
Query 3: count of events by event name, specific date range
This query should benefit from partitioning, even though I constructed it to cross monthly partitions.
SELECT eventname, count(distinct eventid)
FROM "default"."firehose_iceberg"
WHERE eventtime BETWEEN from_iso8601_timestamp('2024-08-17T00:00:00')
AND from_iso8601_timestamp('2024-09-17T00:00:00')
GROUP BY 1
ORDER BY 2 desc
LIMIT 20;
Note: the query against the “monthly aggregation” Parquet files included predicates on the partitioning columns.
| Time (sec) | Data Scanned | |
|---|---|---|
| Parquet, Monthly Aggregation | 1.852 | 19.09 MB |
| Parquet, Firehose | 3.096 | 192.44 MB |
| Iceberg, Firehose | 2.173 | 68.12 MB |
| Iceberg, Partitioned | 4.095 | 36.60 MB |
As expected, the partitioned tables meant far less data scanned … although the compacted Iceberg tables weren’t far behind. The times, however, don’t reflect this, which makes me think that overhead is the main thing I’m measuring, and would need a larger dataset to properly evaluate query performance.
Query 4: specific events on a single day
This is another query that should benefit from partitioning, but has to read all columns to produce results.
SELECT *
FROM "default"."firehose_iceberg"
WHERE eventname = 'DeleteServerlessCache'
AND eventtime BETWEEN from_iso8601_timestamp('2024-08-17T00:00:00')
AND from_iso8601_timestamp('2024-08-17T23:59:59')
Note: the query against the “monthly aggregation” Parquet files included predicates on the partitioning columns.
| Time (sec) | Data Scanned | |
|---|---|---|
| Parquet, Monthly Aggregation | 1.353 | 1.87 MB |
| Parquet, Firehose | 1.367 | 8.80 MB |
| Iceberg, Firehose | 1.791 | 6.26 MB |
| Iceberg, Partitioned | 2.461 | 2.23 MB |
I was expecting “data scanned” to be similar to the previous query, and was surprised that even the Firehose Parquet files were so low. This will require some more investigation.
Wrapping Up
When AWS first announced support for Iceberg tables, I spent some time with them and walked away saying “meh.” I could see how they’d be useful for data that included updates, but most of the work that I did was with append-only datasets. And adding metadata seemed to me to just add overhead.
Automatic table optimization seems like it would go a long way toward overcoming Iceberg’s inefficiencies, but as my queries show, Iceberg consistently underperforms custom-generated Parquet files, and often underperforms those produced by a Firehose.
I suspect the reason is that my 2-or-so GB of data simply isn’t large enough to let Icerberg achieve top performance. Perhaps it would start to show clear benefits with tens or hundreds of GB of data. However, data lakes do not just contain large tables.
Of more concern, it seems that Iceberg is not getting the attention that it deserves within AWS. For example, you can create an Iceberg table in CloudFormation, but you can’t specify partitioning. You can use Athena to create a partitioned Iceberg table, but you can’t change partitioning afterward. In fact, the Athena documentation is littered with suggestions to “contact athena-feedback@amazon.com” to request feature support. And, of course, it would be nice if S3 Table Buckets could be managed and populated using tools other than EMR.