
My last post compared different infrastructure tools for creating users and letting them assume roles for cross-account access. I received a few questions about the underlying problem that those scripts were trying to solve, so this post delves a bit deeper into the realm of user management.
The underlying problem: how do you manage multiple AWS deployments? The typical example is development/qa/production, but developer sandboxes — in which developers have the freedom to experiment with services without fear of impacting anyone else — are perhaps even more relevant. The standard answer to this problem is to create multiple AWS accounts, and with the release of AWS Organizations in 2017 it became much easier to implement: in addition to simplifying billing, Organizations gives the master account more control over the children via Service Control Policies.
But if you use multiple accounts, how do you manage users in those accounts? One not-very-good answer is to create separate users in each account. This quickly becomes a management nightmare, both for the organization and your users. For the organization, you need to add users to the appropriate accounts, manage their permissions, and remove them if they leave the company; this can be solved with automation. But for users, it’s harder to solve: I’ve watched coworkers cycle through a list of accounts/passwords until they found the right one for the task they were about to do. And inevitably, if you’re working with multiple accounts you end up with an “oops!” where you did something in the wrong account.
A better solution is Amazon’s Single Sign-On service, also introduced in 2017. With this service, you can manage a single set of users and grant them varying permissions in different AWS accounts. The users sign in via the SSO portal and select their destination account; they can either get temporary credentials for CLI/SDK access, or be redirected to the AWS Console for that account. In addition, you can use SSO as a portal for web applications such as Office365 or your own SAML-based applications. And you can use a corporate Active Directory server as the user database, which is something that larger organizations will like (disclosure: I haven’t configured AD integration, so can’t say how easy or difficult it is).
When I first wrote this post, I pointed out that SSO did not support TOTP for multi-factor authentication. This changed in October 2019, and you can now use any MFA token provider with SSO that you could use with IAM. However, my second concern remains: SSO is not scriptable (at least as-of this writing) via either CloudFormation or Terraform. So you have to enter your users and configure their permissions manually. And SSO “permission sets” translate directly to IAM roles, so you’ll end up with a mix of scripted and unscripted roles, losing the benefit of source-control for your infrastructure.
With all that said, I still think that SSO is a good choice for many organizations. But I prefer the following architecture, in which all users are defined in the organization’s master account, and have the ability to assume roles in the child accounts (note: each account has a made-up account ID that’s used in subsequent examples):
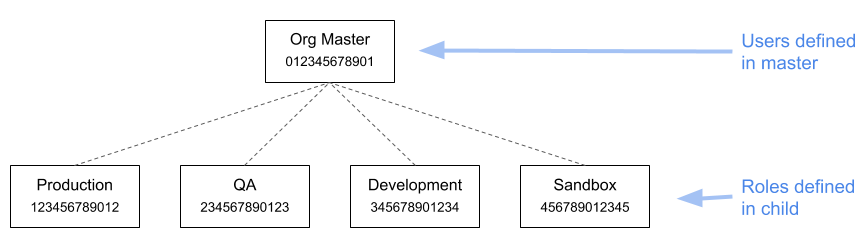
Let’s start by looking at roles. The sandbox account might have only a single role, SandboxUser, which grants administrator access. By comparison, the production account might have multiple roles, granting different levels of access to different sets of resources. For example, you could define a FooMonitoring role that (among other things) grants permission to describe EC2 instances that have an Application tag with the value Foo.
The one thing that all roles will have in common is a trust relationship that allows them to be assumed by users in the master account:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::012345678901:root"
},
"Action": "sts:AssumeRole"
}
]
}
This trust relationship means the role can be assumed by any user in the organizational master account who is allowed the sts:AssumeRole action. This privilege is granted via policies in the master account, and in keeping with AWS best practice, those policies should be attached to groups rather than individual users.
As a concrete example, let’s assume that we have an application named Alfie (I’m getting tired of Foo and Bar). The developers who work on that application should have different levels of access to the resources used by that application depending on environment: full access in development, access for deployments in QA, and read-only access in production. Each level of access will require a role in the relevant account; the specifics of these roles are beyond the scope of this post.
After creating the roles, we’d then create an alfie-developers group in the master account, assign the developers to that group, and give it a permissions policy that looks like the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": [
"arn:aws:iam::123456789012:role/AlfieReadOnly",
"arn:aws:iam::234567890123:role/AlfieDeployment",
"arn:aws:iam::345678901234:role/AlfieFullAccess"
]
}
]
}
All well and good, but how do your users work in this environment?
As long as you stick with the AWS Console, it’s easy to switch roles.
From the command line it’s a little more difficult. The simplest option is to update your AWS configuration files, stored in $HOME/.aws. There are two files, credentials and config, and while in practice you can specify assumable roles in either, the docs are very explicit that the former is only for actual credentials. Assuming that you ran aws configure, it will look like this:
[default] aws_access_key_id = AKIAEXAMPLEXXXXXXXXX aws_secret_access_key = EXAMPLExxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
In the second file, config, you can specify multiple profiles (you also have a default profile in this file, where you can specify your default region):
[default] region = us-east-1 [profile alfie-development] role_arn = arn:aws:iam::345678901234:role/AlfieFullAccess source_profile = default [profile alfie-qa] role_arn = arn:aws:iam::234567890123:role/AlfieDeployment source_profile = default [profile alfie-production] role_arn = arn:aws:iam::123456789012:role/AlfieReadOnly source_profile = default
With these profiles configured, you can use the --profile command-line parameter to specify which role you want to assume for a particular action:
aws s3 ls --profile alfie-development
This is somewhat onerous, and it isn’t available for programs that you write. As an alternative, you can use the AWS_PROFILE environment variable to configure your profile:
export AWS_PROFILE=alfie-development aws s3 ls
There is one final caveat: an assumed role has a limited duration, by default one hour. With the commend line tools and a configured profile, you should never run into this, because each invocation assumes its own role. But in the Console, you may get an “access denied” error, or a popup message telling you to reload. Doing so will refresh your role and you can keep going for another hour.
To wrap up: you may consider switching roles to be a lot of work. But in practice, developers get used to doing it in short order, and prefer not having to juggle credentials. And a more important benefit is that you can then introduce special roles for destructive operations, such as shutting down an RDS instance.