
Triggering a Lambda by uploading a file to S3 is one of the introductory examples of the service. As a tutorial, it can be implemented in under 15 minutes with canned code, and is something that a lot of people find useful in real life. But the tutorials that I’ve seen only look at the “happy path”: they don’t explore what happens (and how to recover) when things go wrong. Nor do they look at how the files get into S3 in the first place, which is a key part of any application design.
This post is a “deep dive” on the standard tutorial, looking at architectural decisions and operational concerns in addition to the simple mechanics of triggering a Lambda from an S3 upload.
Architecture
As the title says, the architecture uses two buckets and a Lambda function. The client uploads a file to the first (“staging”) bucket, which triggers the Lambda; after processing the file, the Lambda moves it into the second (“archive”) bucket.

Why two buckets?
From a strictly technical perspective, there’s no need to have two buckets. You can configure an S3 trigger to fire when a file is uploaded with a specific prefix, and could move the file to a different prefix after processing, so could keep everything within a single bucket. You might also question the point of the archive bucket entirely: once the file has been processed, why keep it? I think there are several answers to this question, each from a different perspective.
First, as always, security: two buckets minimize blast radius. Clients require privileges to upload files; if you accidentally grant too broad a scope, the files in the staging bucket might be compromised. However, since files are removed from the staging bucket after they’re processed, at any point in time that bucket should have few or no files in it. This assumes, of course, that those too-broad privileges don’t also allow access to the archive bucket. One way to protect against that is to adopt the habit of narrowly-scoped policies, that grant permissions on a single bucket.
Configuration management also becomes easier: with a shared bucket, everything that touches that bucket — from IAM policies, to S3 life-cycle policies, to application code — has to be configured with both a bucket name and a prefix. By going to two buckets, you can eliminate the prefix (although the application might still use prefixes to separate files, for example by client ID).
Failure recovery and bulk uploads are also easier when you separate new files from those that have been processed. In many cases it’s a simple matter of moving the files back into the upload bucket to trigger reprocessing.
How do files get uploaded?
All of the examples that I’ve seen assume that a file magically arrives in S3; how it gets there is “left as an exercise for the reader.” However, this can be quite challenging for real-world applications, especially those running in a user’s browser. For this post I’m going to focus on two approaches: direct PUT using a presigned URL, and multi-part upload using the JavaScript SDK.
Pre-signed URLs
Amazon Web Services are, in fact, web services: every operation is implemented as an HTTPS request. For many services you don’t think about that, and instead interact with the service via an Amazon-provided software development kit (SDK). For S3, however, the web-service nature is closer to the surface: you can skip the SDK and download files with GET, just as when interacting with a website, or upload files with a PUT or POST.
The one caveat to interacting with S3, assuming that you haven’t simply exposed your bucket to the world, is that these GETs and PUTs must be signed, using the credentials belonging to a user or role. The actual signing process is rather complex, and requires access credentials (which you don’t want to provide to an arbitrary client, lest they be copied and used for nefarious purposes). As an alternative, S3 allows you to generate a pre-signed URL, using the credentials of the application generating the URL.
Using the the S3 SDK, generating a presigned URL is easy: here’s some Python code (which might be run in a web-service Lambda) that will create a pre-signed URL for a PUT request. Note that you have to provide the expected content type: a URL signed for text/plain can’t be used to upload a file with type image/jpeg.
s3_client = boto3.client('s3')
params = {
'Bucket': bucket,
'Key': key,
'ContentType': content_type
}
url = s3_client.generate_presigned_url('put_object', params)
If you run this code you’ll get a long URL that contains all of the information needed to upload the file:
https://example.s3.amazonaws.com/example?AWSAccessKeyId=AKIA3XXXXXXXXXXXXXXX&Signature=M9SbH6zl9LpmM6%2F2POBk202dWjI%3D&content-type=text%2Fplain&Expires=1585003481
Important caveat: just because you can generate a presigned URL doesn’t mean the URL will be valid. For this example, I used bogus access credentials and a referred to a bucket and key that (probably) doesn’t exist (certainly not one that I control). If you paste it into a browser, you’ll get an “Access Denied” response (albeit due to expiration, not invalid credentials).
To upload a file, your client first requests the presigned URL from the server, then uses that URL to upload the file (in this example, running in a browser, selectedFile was populated from a file input field and content is the result of using a FileReader to load that file).
async function uploadFile(selectedFile, content, url) {
console.log("uploading " + selectedFile.name);
const request = {
method: 'PUT',
mode: 'cors',
cache: 'no-cache',
headers: {
'Content-Type': selectedFile.type
},
body: content
};
let response = await fetch(url, request);
console.log("upload status: " + response.status);
}
Multi-part uploads
While presigned URLs are convenient, they have some limitations. The first is that objects uploaded by a single PUT are limited to 5 GB in size. While this may be larger than anything you expect to upload, there are some use cases that will exceed that limit. And even if you are under that limit, large files can still be a problem to upload: with a fast, 100Mbit/sec network dedicated to one user, it will take nearly two minutes to upload a 1 GB file — two minutes in which your user’s browser sits, apparently unresponsive. And if there’s a network hiccup in the middle, you have to start the upload over again.
A better alternative, even if your files aren’t that large, is to use multi-part uploads with a client SDK. Under the covers, a multi-part upload starts by retrieving a token from S3, then uses that token to upload chunks of the files (typically around 10 MB each), and finally marks the upload as complete. I say “under the covers” because all of the SDKs have a high-level interface that handles the details for you, including resending any failed chunks.
However, this has to be done with a client-side SDK: you can’t pre-sign a multi-part upload. Which means you must provide credentials to that client. Which in turn means that you want to limit the scope of those credentials. And while you can use Amazon Cognito to provide limited-time credentials, you can’t use it to provide limited-scope credentials: all Cognito authenticated users share the same role.
To provide limited-scope credentials, you need to assume a role that has general privileges to access the bucket while applying a “session” policy that restricts that access. This can be implemented using a Lambda as an API endpoint:
sts_client = boto3.client('sts')
role_arn = os.environ['ASSUMED_ROLE_ARN']
session_name = f"{context.function_name}-{context.aws_request_id}"
response = sts_client.assume_role(
RoleArn=role_arn,
RoleSessionName=session_name,
Policy=json.dumps(session_policy)
)
creds = response['Credentials']
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'access_key': creds['AccessKeyId'],
'secret_key': creds['SecretAccessKey'],
'session_token': creds['SessionToken'],
'region': os.environ['AWS_REGION'],
'bucket': bucket
})
}
Even if you’re not not familiar with the Python SDK, this should be fairly easy to follow: STS (the Security Token Service) provides an assume_role method that returns credentials. The specific role isn’t particularly important, as long as it allows s3:PutObject on the staging bucket. However, to restrict that role to allow uploading a single file, you must use a session policy:
session_policy = {
'Version': '2012-10-17',
'Statement': [
{
'Effect': 'Allow',
'Action': 's3:PutObject',
'Resource': f"arn:aws:s3:::{bucket}/{key}"
}
]
}
On the client side, you would use these credentials to construct a ManagedUpload object, then
use it to perform the upload. As with the prior example, selectedFile is set using an input
field. Unlike the prior example, there’s no need to explicitly read the file’s contents into a buffer; the
SDK does that for you.
async function uploadFile(selectedFile, accessKeyId, secretAccessKey, sessionToken, region, bucket) {
AWS.config.region = region;
AWS.config.credentials = new AWS.Credentials(accessKeyId, secretAccessKey, sessionToken);
console.log("uploading " + selectedFile.name);
const params = {
Bucket: bucket,
Key: selectedFile.name,
ContentType: selectedFile.type,
Body: selectedFile
};
let upload = new AWS.S3.ManagedUpload({ params: params });
upload.on('httpUploadProgress', function(evt) {
console.log("uploaded " + evt.loaded + " of " + evt.total + " bytes for " + selectedFile.name);
});
return upload.promise();
}
If you use multi-part uploads, create a bucket life-cycle rule that deletes incomplete uploads. If you don’t do this, you might find an ever-increasing S3 storage bill for your staging bucket that makes no sense given the small number of objects in the bucket listing. The cause is interrupted multi-part uploads: the user closed their browser window, or lost network connectivity, or did something else to prevent the SDK from marking the upload complete. Unless you have a life-cycle rule, S3 will keep (and bill for) the parts of those uploads, in the hope that someday a client will come back and either complete them or explicitly abort them.
You’ll also need a CORS configuration on your bucket that (1) allows both PUT and POST requests, and (2) exposes the ETag header.
Work At Chariot
If you value continual learning, a culture of flexibility and trust, and being surrounded by colleagues who are curious and love to share what they’re learning (with articles like this one, for example!) we encourage you to join our team. Many positions are remote — browse open positions, benefits, and learn more about our interview process below.
A prototypical transformation Lambda
In this section I’m going to call out what I consider “best practices” when writing a Lambda. My implementation language of choice is Python, but the same ideas apply to any other language.
The Lambda handler
I like Lambda handlers that don’t do a lot of work inside the handler function, so my prototypical Lambda looks like this:
import boto3
import logging
import os
import urllib.parse
archive_bucket = os.environ['ARCHIVE_BUCKET']
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
s3_client = boto3.client('s3')
def lambda_handler(event, context):
print(json.dumps(event))
for record in event.get('Records', []):
eventName = record['eventName']
bucket = record['s3']['bucket']['name']
raw_key = record['s3']['object']['key']
key = urllib.parse.unquote_plus(raw_key)
try:
logger.info(f"processing s3://{bucket}/{key}")
process(bucket, key)
logger.info(f"moving s3://{bucket}/{key} to s3://{archive_bucket}/{key}")
archive(bucket, key)
except Exception as ex:
logger.exception(f"unhandled exception processing s3://{bucket}/{key}")
def process(bucket, key):
// do something here
pass
def archive(bucket, key):
s3_client.copy(
CopySource={'Bucket': bucket, 'Key': key },
Bucket=archive_bucket,
Key=key)
s3_client.delete_object(Bucket=bucket, Key=key)
Breaking it down:
- I get the name of the archive bucket from an environment variable (the name of the upload bucket is part of the invocation event).
- I’m using the Python logging module for all output. Although I don’t do it here, this lets me write JSON log messages, which are easier to use with CloudWatch Logs Insights or import into Elasticsearch.
- I create the S3 client outside the Lambda handler. In general, you want to create long-lived clients outside the handler so that they can be reused across invocations. However, at the same time you don’t want to establish network connections when loading a Python module, because that makes it hard to unit test. In the case of the Boto3 library, however, I know that it creates connections lazily, so there’s no harm in creating the client as part of module initialization.
- The handler function loops over the records in the event. One of the common mistakes that I see with event-handler Lambdas is that they assume there will only be a single record in the event. And that may be right 99% of the time, but you still need to write a loop.
- The S3 keys reported in the event are URL-encoded; you need to decode the key before passing it to the SDK. I use urllib.parse.unquote_plus(), which in addition to handling “percent-encoded” characters, will translate a
+into a space. - For each input file, I call the
process()function followed by thearchive()function. This pair of calls is wrapped in a try-catch block, meaning that an individual failure won’t affect the other files in the event. It also means that the Lambda runtime won’t retry the event (which would almost certainly have the same failure, and which would mean that “early” files would be processed multiple times). - In this example
process()doesn’t do anything; in the real world this is where you’d put most of your code. - The
archive()function moves the file as a combined copy and delete; there is no built-in “move” operation (again, S3 is a web-service, so is limited to the six HTTP “verbs”).
Don’t store files on attached disk
Lambda provides 512 MB of temporary disk space. It is tempting to use that space to buffer your files during processing, but doing so has two potential problems. First, it may not be enough space for your file. Second, and more important, you have to be careful to keep it clean, deleting your temporary files even if the function throws an exception. If you don’t, you may run out of space due to repeated invocations of the same Lambda environment.
There are alternatives. The first, and easiest, is to download the entire file into RAM and work with it there. Python makes this particularly easy with its BytesIO object, which behaves identically to on-disk files. You may still have an issue with very large files, and will have to configure your Lambda with enough memory to hold the entire file (which may increase your per-invocation cost), but I believe that the simplified coding is worth it.
You can also work with the response from an S3 GET request as a stream of bytes. The various SDK docs caution against doing this: to quote the Java SDK, “the object contents […] stream directly from Amazon S3.” I suspect that this warning is more relevant to multi-threaded environments such as a Java application server, where a long-running request might block access to the SDK connection pool. For a single-threaded Lambda, I don’t see it as an issue.
Of more concern, the SDK for your language might not expose this stream in a way that’s consistent with standard file-based IO. Boto3, the Python SDK, is one of the offenders: its get_object() function returns a StreamingBody, which has its own methods for retrieving data and does not follow Python’s io library conventions.
A final alternative is to use byte-range retrieves from S3, using a relatively small buffer size. I don’t think this is a particularly good alternative, as you will have to handle the case where your data records span retrieved byte ranges.
IAM Permissions
The principle of least privilege says that this Lambda should only be allowed to read and delete objects in the upload bucket, and write objects in the archive bucket (in addition to whatever permissions are needed to process the file). I like to manage these permissions as separate inline policies in the Lambda’s execution role (shown here as a fragment from the CloudFormation resource definition):
Policies:
-
PolicyName: "ReadFromSource"
PolicyDocument:
Version: "2012-10-17"
Statement:
Effect: "Allow"
Action:
- "s3:DeleteObject"
- "s3:GetObject"
Resource: [ !Sub "arn:${AWS::Partition}:s3:::${UploadBucketName}/*" ]
-
PolicyName: "WriteToDestination"
PolicyDocument:
Version: "2012-10-17"
Statement:
Effect: "Allow"
Action:
- "s3:PutObject"
Resource: [ !Sub "arn:${AWS::Partition}:s3:::${ArchiveBucketName}/*" ]
I personally prefer inline role policies, rather than managed policies, because I like to tailor my roles’ permissions to the applications that use them. However, a real-world Lambda will require additional privileges in order to do its work, and you may find yourself bumping into IAM’s 10kb limit for inline policies. If so, managed policies might be your best solution, but I would still target them at a single application.
Handling duplicate and out-of-order invocations
In any distributed system you have to be prepared for messages to be resent or sent out of order; this one is no different. The standard approach to dealing with this problem is to make your handlers idempotent: writing them in such a way that you can call them multiple times with the same input and get the same result. This can be either very easy or incredibly difficult.
On the easy side, if you know that you’ll only get one version of a source file and the processing step will always produce the same output, just run it again. You may pay a little more for the excess Lambda invocations, but that’s almost certainly less than you’ll pay for developer time to ensure that the process only happens once.
Where things get difficult is when you have to deal with concurrently processing different versions of the same file: version 1 of a file is uploaded, and while the Lambda is processing it, version 2 is uploaded. Since Lambdas are spun up as needed, you’re likely to have a race condition with two Lambdas processing the same file, and whichever finishes last wins. To deal with this you have to implement some way to keep track of in-process requests, possibly using a transactional database, and delay or abort the second Lambda (and note that a delay will turn into an abort if the Lambda times-out).
Another alternative is to abandon the simple “two buckets” pattern, and turn to an approach that uses a queue. The challenge here is providing concurrency: if you use a queue to single-thread file processing, you can easily find yourself backed up. One solution is multiple queues, with uploaded files distributed to queues based on a name hash; a multi-shard Kinesis topic gives you this hashing by design.
In a future post I’ll dive into these scenarios; for now I merely want to make you aware that they exist and should be considered in your architecture.
What if the file’s too big to be transformed by a Lambda?
Lambda is a great solution for asynchronously processing uploads, but it’s not appropriate for all situations. It falls down with large files, long-running transformations, and many tasks that require native libraries. One place that I personally ran into those limitations was video transformation, with files that could be up to 2 GB and a a native library that was not available in the standard Lambda execution environment.
There are, to be sure, ways to work-around all of these limitations. But rather than shoehorn your big, long-running task into an environment designed for short tasks, I recommend looking at other AWS services.
The first place that I would turn is AWS Batch: a service that runs Docker images on a cluster of EC2 instances that can be managed by the service to meet your performance and throughput requirements. You can create a Docker image that packages your application with whatever third-party libraries that it needs, and use a bucket-triggered Lambda to invoke that image with arguments that identify the file to be processed.
When shifting the file processing out of Lambda, you have to give some thought to how the overall pipeline looks. For example, do you use Lambda just as a trigger, and rely on the batch job to move the file from staging bucket to archive bucket? Or do you have a second Lambda that’s triggered by the CloudWatch Event indicating the batch job is done? Or do you use a Step Function? These are topics for a future post.
Wrapping up: a skeleton application
I’ve made an example project available on GitHub. This example is rather more complex than just a Lambda to process files:
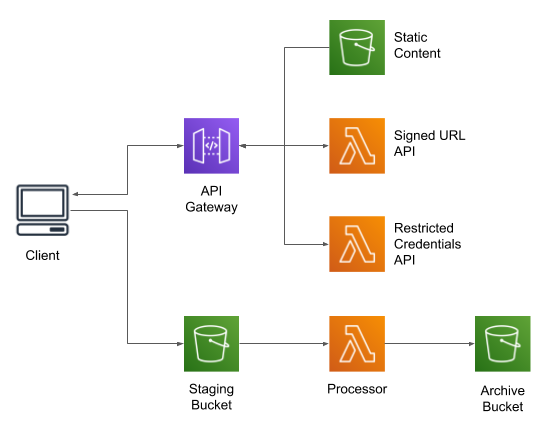
The core of the project is a CloudFormation script to build-out the infrastructure; the project’s README file gives instructions on how to run it. This example doesn’t use any AWS services that have a per-hour charge, but you will be charged for the content stored in S3, for API Gateway requests, and for Lambda invocations.