I like Terraform: I think it provides a nice balance between conciseness and capability. But I’ve noticed that many of Chariot’s clients — from 4-person startups to 40,000-person multinationals — are sticking with CloudFormation. And I can understand why.
There are several benefits to CloudFormation. For one thing, it’s part of AWS, whereas Terraform must be downloaded, installed, and regularly updated. And a CloudFormation stack is also “built in,” in the sense that everything about that stack is visible from the AWS Console, whereas Terraform uses external tfstate files to track deployment information. And, of course, it means that you can get support directly from Amazon, rather than hiring a third-party consultant.
However, as I’ve said before, CloudFormation can be verbose and unwieldy. This post highlights some of the tricks that I’ve learned while working with it over the last half-dozen years, and are meant to complement the best practices described in the CloudFormation user guide.
Start by building your infrastructure by hand
This advice applies to your first template for a service (for the second and subsequent, see “great writers steal”). When you’re just getting started with a service, you need to experiment and understand how it works, and there’s no better place to do that than the AWS Console. Once you fully understand how the service works, and how you want to configure it for your application, then it’s time to capture that knowledge as a template.
I find that the easiest way to do this is to use the command-line tool’s “describe” operations. For example, let’s say that you’ve hand-crafted a CloudWatch alarm for an auto-scaling group. You can then run aws cloudwatch describe-alarms, and its output has nearly a 1:1 correspondence to the CloudFormation AWS::CloudWatch::Alarm configuration.
Once you’ve transferred the resource configuration to a template, you can then decide whether you want to import the hand-crafted resource or delete it and re-create using the template. I lean toward the latter, but the former lets you verify that you correctly defined the resource.
Create templates incrementally
It’s tempting to write an entire template and then create a stack from it, especially if you’ve written many similar templates in the past. Avoid this temptation, because a single typo will cause the entire operation to fail. And if you have resources (like CloudFront distributions) that take a long time to create and tear down, such failures can waste an enormous amount of time.
Instead, I start new stacks with a single resource, typically a role definition. Once the stack is created, I add a few resources at a time, updating the stack after each edit. If one of those resources has a problem, the update will fail, but typically that won’t take too long to fix. And unlike an initial stack failure, which requires you to delete the stack before starting over, an update can be rerun as many times as you need; the existing stack resources remain untouched.
Use the AWS Console to create/update stacks, at least during development
For production deployments, you’ll probably use the command-line tool to deploy your stacks. At this point in time, everything’s complete, configuration is known, and you’re just stamping out environments.
During development, however, it’s a lot simpler to step through the console wizard to select your template, define parameters, and create or update your stack. And if your parameters use AWS-specific types (for example, a list of security group IDs), the console will helpfully list the available IDs in the destination region.
But the real reason to use the console, especially for updates, is best explained with a picture:
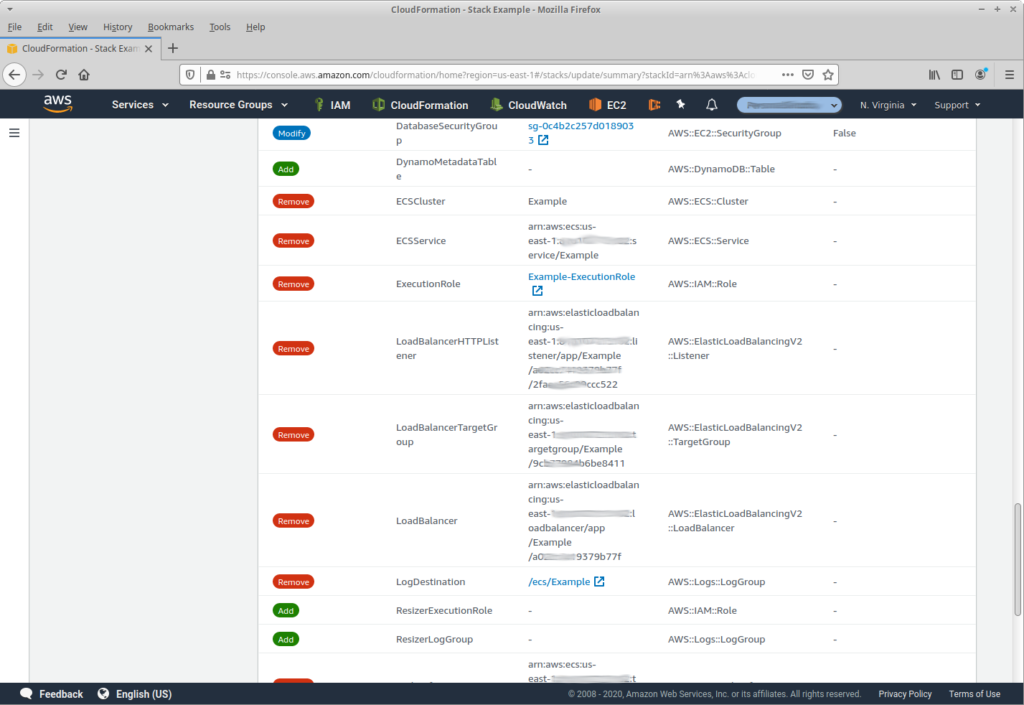
This is a case where I picked the wrong template for an update; if you’re managing lots of stacks, it’s easy to do. If I had made my update from the command-line, I wouldn’t realize my mistake until it had already caused damage. While the CloudFormation User Guide recommends creating change-sets rather than direct updates to avoid just this problem, I find it easier (and faster) to use the Console and wait to see the change list before clicking “Update”.
Use outputs lavishly, exports sparingly
Many of the resources that your stack creates have some attributes that are useful outside of the stack. For example, the hostname of a load balancer or RDS database instance. I encourage you to report these values using the Outputs section of your template. Then you can use a tool like this to retrieve those output values and use them in your development environment.
I’m less enamored of exporting those values and using them in cross-stack references. There are several rules that you have to follow when using such references, the most important being that you can’t modify a resource that’s been imported into another stack. I have been burned far too often by trying to change a stack that was depended-on by other stacks.
One area where I do consider exports useful is for “deep infrastructure” resources like VPCs and subnets. These are unlikely to change once you have your architecture defined, and many other resources rely on knowing them. Even in this case you might run into the problem that export names must be unique per region/account, so if you have two VPCs you’ll either need to create them in the same stack or come up with a convention for their names.
Establish conventions and stick to them
And that leads me to one of the most important techniques for maintainable stacks: a naming convention. For example, let’s say that you’re creating a Lambda function Foo; you know that function will need an execution role, so do yourself a favor and name it role Foo-ExecutionRole.
Of course, this simple convention breaks down if you’re creating the Foo function in multiple regions, because IAM roles must have unique names within an account. In this case, add the destination region into the role name: Foo-ExecutionRole-us-west-1.
Another approach (which I prefer) is to give the stack a “base name” that’s provided as a parameter, and prefix all resource names with that base name. This approach also lets you visually categorize the resources when you see them in a list: you know that the Argle-Foo Lambda function was created in a stack with the base name Argle, while the Bargle-Foo function was created in a stack with the base name Bargle. Alternatively, prefix all of the names with the stack’s own name.
Conventions shouldn’t be limited to just the names of the physical resources that the stack produces. Your life will also be easier if you make the logical IDs inside the template follow a convention: FooFunction, FooFunctionRole, and FooFunctionLogGroup make it a lot easier to navigate your way through the stack.
At least as important is to adopt a naming convention for parameters. If every stack uses VpcId to identify the deployment VPC, and PublicSubnets to identify public subnets in that VPC, then you can leverage copy-paste coding to your advantage (see below). Or write a tool that pre-populates these parameters.
Fn::Sub is the most underrated intrinsic function
When generating names or other text, you might think of using the Fn::Join intrinsic function (this example adapted from a CDK-generated template):
ManagedPolicyArns:
- Fn::Join:
- ""
- - "arn:"
- Ref: AWS::Partition
- ":iam::"
- Ref: AWS::AccountId
- ":policy/BasicUserPolicy"
It’s far easier (both when writing the template and when reading it afterward) to use the Fn::Sub function:
ManagedPolicyArns:
- Sub! "arn:${AWS::Partition}:iam::${AWS::AccountId}:policy/BasicUserPolicy"
Fn::Sub can also take the place of the Ref and Fn:GetAtt functions: you just need to reference the resource logical ID:
Resource: [ !Sub "${ElasticSearchDomain.Arn}/*" ]
Related: don’t forget to leverage pseudo-parameters such as AWS::AccountId or AWS::Region; these two are particularly useful for building ARNs. And there’s also AWS::StackName, which can be used to construct names that are unique to a stack.
Avoid macros and custom resources
Macros and custom resources are two ways to work-around the static, declarative nature of a CloudFormation template: the former allows you to transform portions of your template before CloudFormation executes it, while the latter allows you to perform imperative actions that are tied into the life-cycle of the stack. The prototypical example — which could be implemented using either technique — is to discover the default VPC for the deployment region, along with its public/private subnets.
My feeling on both of these is covered by the old meme about regular expressions: you have a problem, so you think “hey, I’ll use a (custom resource|macro).” Now you have two problems.
And I mean that quite literally, because before you can use a custom resource or macro, you need to create the infrastructure that implements it (typically a Lambda function). That usually means another CloudFormation stack. And if that infrastructure has problems — or changes in ways that are incompatible with your stack — you are in for a world of pain.
There are some reasons to use custom resources. For example, if you’re implementing a multi-vendor architecture, and need to create resources in some other cloud. But if I were to do this, I would strongly push for a switch to Terraform.
Avoid external tools
Yes, I’m looking at you, SAM.
For those who aren’t familiar, the Serverless Application Model is a toolchain for developing and deploying Lambda functions and related infrastructure. Deployment is handled with a CloudFormation extension that simplifies defining an API and the function(s) that implement it. The SAM command-line tool (CLI) lets you package all needed resources and upload them to an S3 bucket before deploying the template.
That sounds reasonable, but the implementation leaves a lot to be desired. The actual SAM CLI is a Python program (like the awscli), but has a lot of dependencies. So rather than package it as a Python module that can be installed with pip, the developers packaged it using Homebrew (or a Windows installer module). Which is fine, I suppose, if you’re a single developer working on your Mac. But if you work on Linux, or are configuring a CI/CD server to build and deploy your applications, it’s a royal pain (and one reason that I use a virtual machine for SAM workspaces).
Note that I’m not saying “don’t use external tools.” But be aware that every tool has both costs and benefits, and you need to decide whether the latter outweighs the former.
Don’t be afraid to generate your templates
One example where a tool (in this case, a home-grown tool) would be useful: I’m currently working with a client that is building complex CloudFormation templates, including nested stacks for reusable code templates. They’re creating a lot of these templates, so sooner or later they’re going to bump into the limit of 200 stacks per account/region.
I think that the best solution for them is to use a Python script to generate self-contained templates. Where there’s repeated content, it can be generated with multiple calls to a function. This is a reasonable solution for CloudFormation, which uses JSON to represent infrastructure; it might not be a reasonable solution for a different deployment tool.
If you start down this path, you might also consider implementing a “deploy” operation in addition to the “generate” operation; it would retrieve information about the deployment environment such as VPC ID and subnets, and provide that information as parameters. And while I can empathize with that desire, beware that it’s a slippery slope. If you go too far you will re-implement CDK or Terraform.
Always remember: great (template) writers steal
Copy-paste coding has a deservedly bad reputation, with a stereotyped developer who copies code from Stack Overflow without understanding how it works. And to some extent, that applies to CloudFormation templates as well: if you don’t know what a VPC is, you probably shouldn’t be creating one.
But assuming that you do know what your templates are doing, you can save an enormous amount of time by copying pieces from one template into another. That’s one reason that my personal projects all include CloudFormation templates: I know that I can turn to one or more of them to find tested resource definitions.
AWS also provides many example templates. My one concern with these examples is that they tend to over-complicate things: for example, the EC2 instance template includes mappings that associate different instance types with the appropriate AWS Linux instance AMI. In a real-world template, you would typically pass that in as a parameter (especially since you’re probably using a custom AMI).