Large Language Model (LLM) chatbots like ChatGPT are all the rage these days. You may be experimenting with building one of your own using a model runtime engine like Ollama, possibly accessing it with the LangChain API, maybe integrating it with a Vector Database for your custom data and using Retrieval Augmented Generation (RAG), or even fine tuning a base model to create one customized for the data you want to access.
Whatever the reason, you’ll quickly find out that your non-NVIDIA GPU-based desktop, old Intel MacBook with integrated graphics, or your custom-build desktop just doesn’t have the horsepower to run things in any speed that approaches reasonable. Maybe the video card isn’t supported by Ollama. Maybe the hardware is too old, or your card has a teensy amount of Video Ram (VRAM).
You may be stuck and wanting to experiment with GPU-accelerated LLM processes. You need, as Scotty says, “more paowah sirrrah!”
How to Get Accelerated
You have a bevy of options to get GPU support for your development efforts, all various levels of expensive:
-
Build your own LLM workhorse – This costs more up front, but then you reap the benefits of running your own GPU and not paying a service. But you've got to fork out the money and get the config right. Sorry, I've built my own PCs and do NOT enjoy this.
-
Buy an M1 Mac and let unified memory access the GPU. All M1 (and M2, 3) chipsets have the memory on the die with the CPU cores and GPU cores, and allow either processor type to access all of the memory. This is great, but you need at least 64GB of high-priced Apple RAM to do realistic workflows. Still, $6k for a workstation that can delay your need for cloud GPUs in development is not a bad investment
-
Managed cloud services – Amazon has a wide variety of cloud services available – including Amazon Kendra which costs $810 / month / developer for the license (yes, there is a free tier of 750 hours available to start), Amazon Bedrock, which is a serverless pay-as-you-go access platform for LLMs, and their many other ML APIs.
-
EC2 instances tuned for GPU work – if you don't want to dig deeply into a managed solution yet, or you may use more than Amazon's own APIs and platforms, and you have a simple workflow to try out on an accelerated platform but no platform to use, try out Amazon's EC2 AMIs.
Using an EC2 Instance for LLM GPU Access
In this article we'll look at a few things you need to be aware of when trying out LLM on an EC2 instance, such as base AMIs, machine instance types and costs, and compatibility with Ollama.
Amazon's EC2 GPU Machine Types
Disclaimer: I am no deep expert in cost optimization operations on AWS with regard to GPUs, and so you need to verify this research yourself in order to not max your credit card when experimenting with AWS instances.
Ollama makes use of GPUs from NVIDIA and Apple Silicon GPUs (AMD may be supported now or in the future, but isn't something we researched).
Realistically that means for EC2 instances, we need to look for NVIDIA-based GPUs on machine types. Amazon has one cost-effective instance classification, the G4 instances. https://aws.amazon.com/ec2/instance-types/g4/
The NVIDIA instances of this class use NVIDIA T4 GPUs, and can be set to use a smaller memory footprint and one GPU, which is good for doing short experiments.
Quoting AWS:
G4dn instances, powered by NVIDIA T4 GPUs, are the lowest cost GPU-based instances in the cloud for machine learning inference and small scale training. They also provide high performance and are a cost-effective solution for graphics applications that are optimized for NVIDIA GPUs using NVIDIA libraries such as CUDA, CuDNN, and NVENC. They provide up to 8 NVIDIA T4 GPUs, 96 vCPUs, 100 Gbps networking, and 1.8 TB local NVMe-based SSD storage and are also available as bare metal instances.
On-demand, but not cheap
Remember, we are renting virtual representations of hardware here, and the bills must be paid. If you have a local hardware option, use it if possible. But if you need to test what a GPU would do to your workload and don't have one, these are an option. But be very careful of pricing and how long you run the instances or bills can rack up.
An example: looking a pricing of a g4dn Intel+NVIDIA instance, we selected the 16GB RAM, 4 VCPU instance type, g4dn.xlarge. This ended up costing (at the time of writing) somewhere around $0.50 / hr plus data transfer fees.
See the Product Details section of https://aws.amazon.com/ec2/instance-types/g4/ for pricing via on-demand and 1 or 3 year reserved instances. Given that LLM tech changes every 1/2 hour, maybe don't rent a 3 year lease on one of these.
Remember, $0.50 / hr is roughly $360 for 30 days, so don't keep these running and forget them! Better to cut an AMI and resurrect them later, or at bare minimum stop the instance after experimentation.
Now that we've selected the g4dn.xlarge, GPU, let's look at getting an OS that recognizes them and installs the right base software and device drivers.
DLAMI AMI instances
The AWS Deep Learning AMI (DLAMI) are a suite of Amazon Machine Images and recommended target instances that pre-install everything you need to get started on a GPU-accelerated ML or LLM project.
For the Intel/NVIDIA chipsets like our g4dn selected above, we'll want one that installs a supported NVIDIA device driver and the CUDA API, which is what Ollama binds to for its accelerated processing.
Specifically, at the time of writing, Ollama needs CUDA beginning with version 11.3, and so if you're not careful and pick an older AMI, you may be out of luck.
Unsure which version of CUDA your EC2 instance (or desktop with CUDA) runs? Just execute:
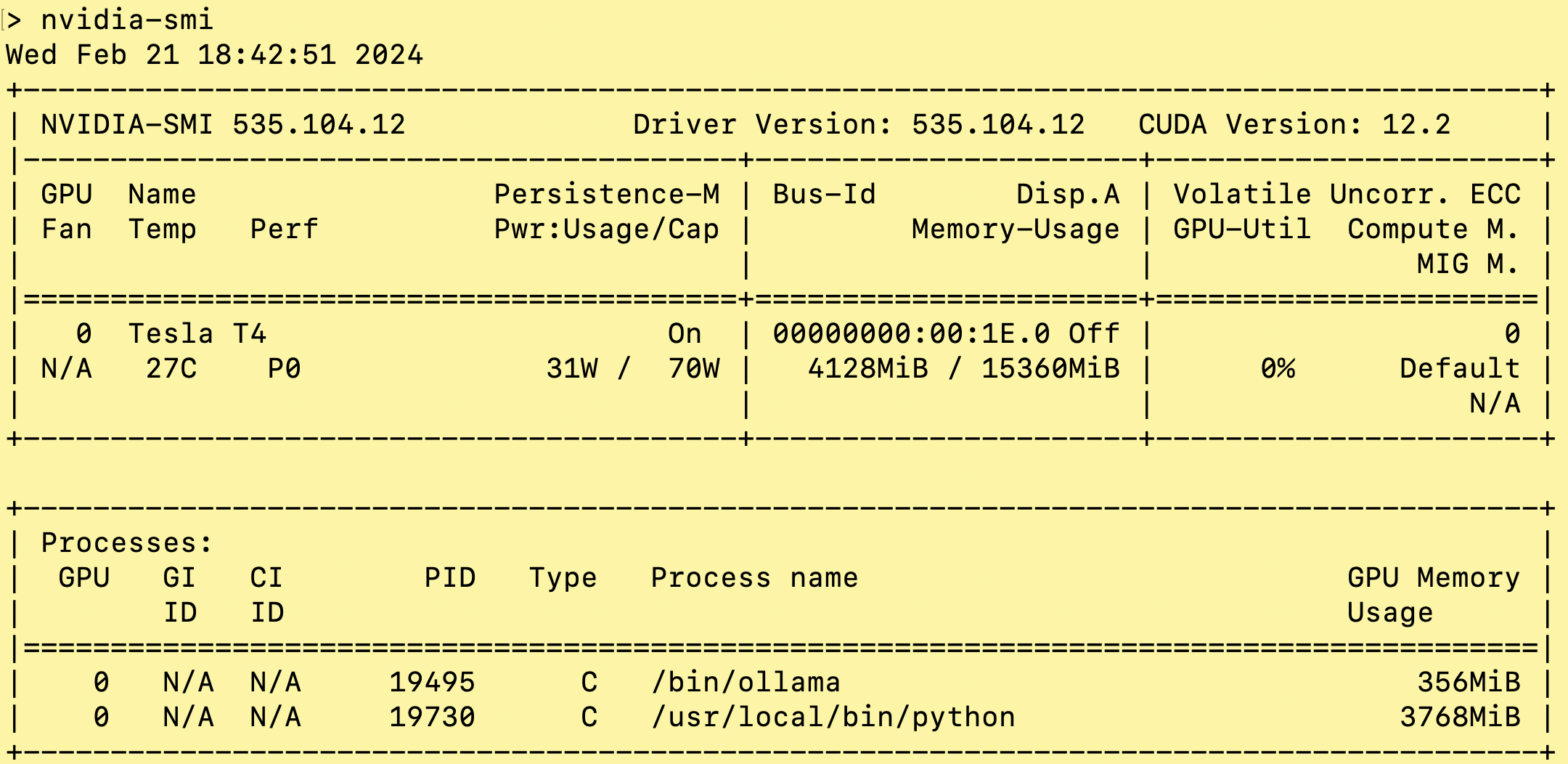
As you see above in "CUDA Version", we're on CUDA 11.6 in the the VM I pulled this from.
Didn't find nvidia-smi? Your NVIDIA drivers and CUDA are probably not installed or aren't configured properly. Drop that EC2 image and try another one, it's costing $0.50 or more an hour. Amazon bills by the minute and prices by the hour, so the quicker you kill the image the less you pay.
A sample DLAMI image – what's on it?
With the AMI I recently used – 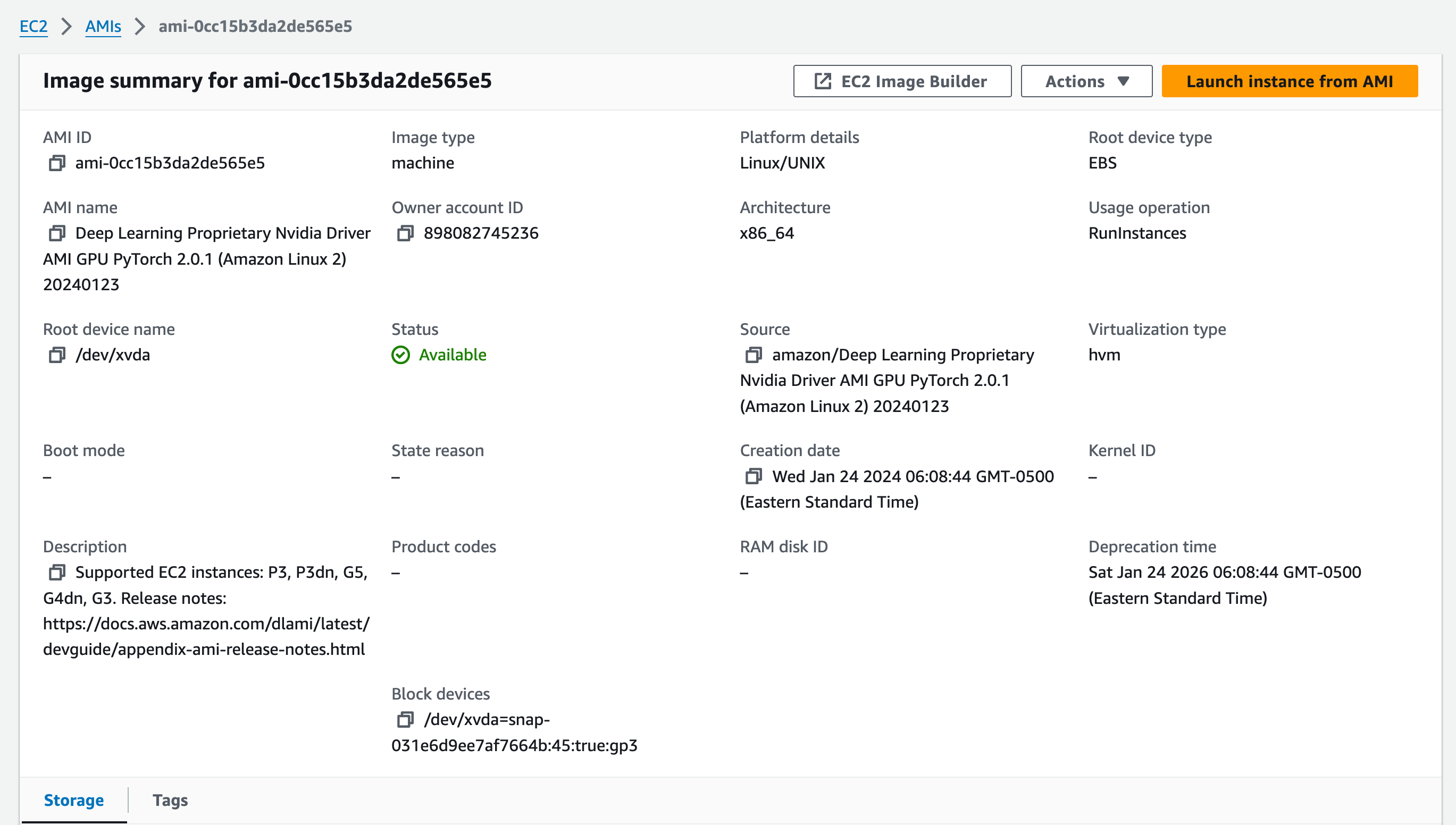
The image above, ami-Occ15b3da2de565e5, contains:
- Amazon Linux 2 as the OS
- The NVIDIA proprietary driver pre-installed
- CUDA support baked in
- Python 3
- PyTorch 2.0.1
- Docker server already installed (BUT NOT
docker-composeand the version of docker is NOT the version withcomposebaked intodocker)
There is other software available as well but this suited my configuration needs perfectly.
See The DLAMI developer's guide for a lot of documentation on what this AMI can do.
Finding the right AMI and other issues
It can be a challenge to find the right AMI to work with, partially because some DLAMIs support one machine classification, and others support yet another. Make sure to pick the one for your machine classification.
I've attempted to upgrade AWS machine instances with older CUDA versions and it's a slight nightmare that can be avoided by selecting a good base AMI. I'm sure an excellent sysadmin with deep knowledge of device drivers and configuration of same can get it done, but you're paying $0.50 an hour, and I sure hope you create your own AMI at the end.
The AMI probably sets up a small single root volume, and you'll run out of space almost right away (that one gave me 7GB of space, so I re-created it with 100GB for my experiments, and still that was not ideal).
You'll also need to know what you're doing on AWS before attempting this, including configuring two-factor authentication, setting up least-privilege access to the instance via security groups and other infrastructure to only those you trust.
If this scares you, consider looking at Amazon Bedrock and Bedrock Knowledge Bases, with their resultant costs, or build your own machine / buy a more expensive mac. You'll pay more up front, but you'll stave off expensive costs until the organization is ready to deploy.
Coming up
In our next article, we'll discuss the ins and outs of using Docker against the GPU on NVIDIA (as well as Mac) chipsets, and whether to run native or virtualized services against the OS.