As part of our research on LLMs, we started working on a chatbot project using RAG, Ollama and Mistral. Our developer hardware varied between Macbook Pros (M1 chip, our developer machines) and one Windows machine with a "Superbad" GPU running WSL2 and Docker on WSL. All hail the desktop with the big GPU.
We planned on deploying to an Amazon EC2 instance as a quick test (running Docker on a g4dn.xlarge instance), and I thought initially that we could use Docker locally to start up the application stack. Then we could deploy it on Windows, Mac and Linux, and everything would run in one quick startup script via docker-compose up.
I built up the docker-compose file to start the whole stack, and hoped everything would be great.
The important parts for our discussion:
version: "3.7"
services:
...
frontend:
env_file:
- ./.env.local
container_name: frontend
build:
context: ./client
dockerfile: Dockerfile
ports:
- "8080:80"
appserver:
env_file:
- ./.env.local
container_name: chariot_chatbot
build:
context: ./appserver
dockerfile: Dockerfile
ports:
- "8000:8000"
ollama:
container_name: ollama
image: ollama/ollama
command: serve
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
Anyone who has been through the process of discovering Apple's differences from Linux/Mac NVIDIA can stop here and say "I told you so." But for the rest of us, I submit my learning process.
Everything was not great
As you can see above, the ollama service is a Docker container that was released in October of 2023. Yay!
I quickly skimmed the blog post announcing it. Do you see what I didn't?

We recommend running Ollama alongside Docker Desktop for MacOS in order for Ollama to enable GPU acceleration for models
— From https://ollama.com/blog/ollama-is-now-available-as-an-official-docker-image
Yeah, so you'll see my folly now. Alongside basically means "DO NOT USE THIS DOCKER CONTAINER".
Anyway, I started pulling together a stack that included an Ollama service. The Ollama Docker container supported GPUs, but the author of this blog post (erm, me) will tell you he didn't RTFM properly. It turns out, Docker does NOT support M1 Mac GPUs.
What was wrong? I assumed it could have been:
- The fact that I was running Docker
- Maybe a problem with the Docker service configuration?
- The M1 GPUs and API?
Macs with their Apple GPUs which use the Metal Performance Shaders API aren't supported as widely as CUDA, NVIDIA's GPU API for machine learning use. There is a reason which I'll get to later in the article.
To prove that, let me show you what the output of the Ollama log looks like when it doesn't detect an Apple Silicon GPU.
Starting Docker Desktop: it does not detect a GPU.
$ docker run ollama/ollama time=2024-02-21T21:09:40.438Z level=INFO source=payload_common.go:146 msg="Dynamic LLM libraries [cuda_v11 cpu]" time=2024-02-21T21:09:40.438Z level=INFO source=gpu.go:94 msg="Detecting GPU type" time=2024-02-21T21:09:40.438Z level=INFO source=gpu.go:265 msg="Searching for GPU management library libnvidia-ml.so" time=2024-02-21T21:09:40.438Z level=INFO source=gpu.go:311 msg="Discovered GPU libraries: []" time=2024-02-21T21:09:40.438Z level=INFO source=gpu.go:265 msg="Searching for GPU management library librocm_smi64.so" time=2024-02-21T21:09:40.438Z level=INFO source=gpu.go:311 msg="Discovered GPU libraries: []" time=2024-02-21T21:09:40.438Z level=INFO source=cpu_common.go:18 msg="CPU does not have vector extensions" time=2024-02-21T21:09:40.438Z level=INFO source=routes.go:1042 msg="no GPU detected"
So, right there, the Docker image isn't being exposed to a GPU, and the only GPU library supported by Docker and viewable as hardware to the image is the NVidia GPU library.
What about other Docker engines like Colima?
Colima is a docker engine that runs as a backend to the Docker CLI if you set it up properly. I had thought I could use this engine and maybe it would expose the Apple Silicon Metal GPU shaders and use them unlike Docker.
Assuming you’ve installed and configured Colima, here’s how you switch to it as a Docker provider context and run Ollama:
$ colima start $ docker context colima $ docker run ollama/ollama time=2024-02-21T20:58:55.265Z level=INFO source=payload_common.go:146 msg="Dynamic LLM libraries [cpu cuda_v11]" time=2024-02-21T20:58:55.265Z level=INFO source=gpu.go:94 msg="Detecting GPU type" time=2024-02-21T20:58:55.265Z level=INFO source=gpu.go:262 msg="Searching for GPU management library libnvidia-ml.so" time=2024-02-21T20:58:55.267Z level=INFO source=gpu.go:308 msg="Discovered GPU libraries: []" time=2024-02-21T20:58:55.267Z level=INFO source=gpu.go:262 msg="Searching for GPU management library librocm_smi64.so" time=2024-02-21T20:58:55.267Z level=INFO source=gpu.go:308 msg="Discovered GPU libraries: []" time=2024-02-21T20:58:55.267Z level=INFO source=cpu_common.go:18 msg="CPU does not have vector extensions" time=2024-02-21T20:58:55.267Z level=INFO source=routes.go:1037 msg="no GPU detected"
No way.
No GPU for Apple in Docker engines
I really dug in and tried to make this work, thinking "this MUST be supported."
I spent a bit of time trying out various settings in both Colima and Docker, none of which did anything more than make the Docker memory footprint bigger (good), increase the number of CPUs (good), yet did not recognize the GPU (bad).
Turns out, even Docker informs us that Docker Desktop on Windows with WSL supports GPU acceleration, not Docker Desktop on Mac:
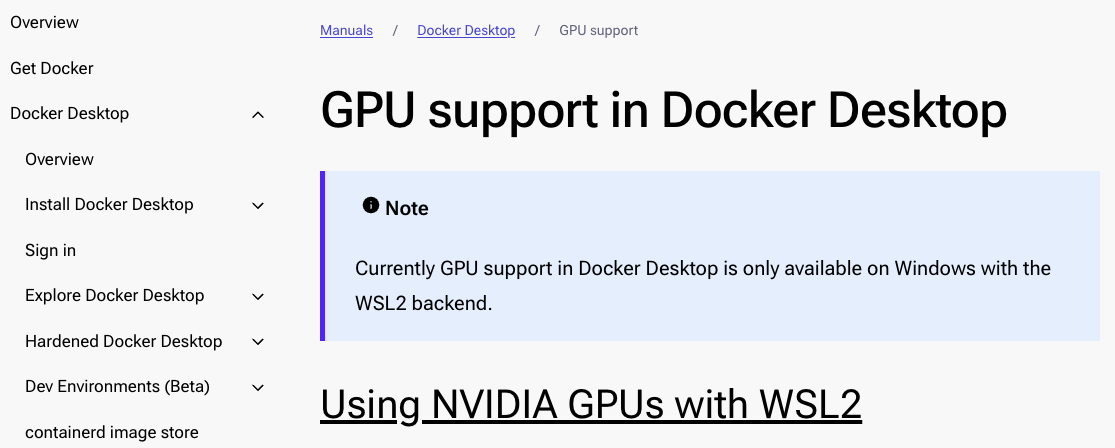
I could have saved myself a lot of time by googling beforehand, but this is how I learn. As my mother used to say "Ken, you always have to find out the hard way. Good luck at school." But hey, the facts are cemented in my brain now: currently Docker on Mac does not see the GPU.
But why?
Virtualization on Macs is the issue
From a really good article on Apple Silicon performance for LLMs from Andreas Kunar (sorry, this blog is a Medium link):
Apple’s mandatory “Apple Virtualization Framework” seems mostly to blame for this, the silicon should technically support it from M2 onwards. Parallels, Docker,… all have to use it — Parallels did their own, better virtualizer for Intel-Macs. There might be hope for future MacOS versions, but I won’t hold my breath for it.
— Andreas Kunar, Thoughts on Apple Silicon Performance for Local LLMs
It turns out that Docker and NVIDIA have a tight relationship when it comes to accelerated graphics. Docker only supports native Linux GPUs (with a supported release of CUDA and an NVIDIA card driver), and on Windows with WSL 2 and and supported video card. Macs are not included because Apple hasn't provided an open GPU API for their mandatory Virtualization engine.
That $5k Mac with a lot of memory is not currently going to support acceleration in Docker.
But Native Ollama Does Support Apple Silicon
Coming back to the beginning of this saga, that vaguely worded sentence basically said "run Ollama locally!"
So I ran Ollama in the terminal to test it out. Note: if you’re running Ollama via the icon at the top of the Mac screen, you can kill it and do this, or `tail -f ~/.ollama/logs/server.log`.
Running Ollama in the terminal:
$ ollama serve time=2024-02-22T10:12:42.723-05:00 level=INFO source=images.go:706 msg="total blobs: 5" time=2024-02-22T10:12:42.724-05:00 level=INFO source=images.go:713 msg="total unused blobs removed: 0" time=2024-02-22T10:12:42.725-05:00 level=INFO source=routes.go:1014 msg="Listening on 127.0.0.1:11434 (version 0.1.25)" time=2024-02-22T10:12:42.725-05:00 level=INFO source=payload_common.go:107 msg="Extracting dynamic libraries..." time=2024-02-22T10:12:42.743-05:00 level=INFO source=payload_common.go:146 msg="Dynamic LLM libraries [metal]"
Do you see that? [metal] is the Dynamic LLM library exposed and available to the engine. So I fired up a mistral engine.
Running my llm chatbot in another terminal:
$ ollama run mistral
The output in the first terminal (there is a lot of it, but only when you activate a model):
llm_load_tensors: offloading 32 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 33/33 layers to GPU llm_load_tensors: CPU buffer size = 70.31 MiB llm_load_tensors: Metal buffer size = 3847.56 MiB ................................................................................................... llama_new_context_with_model: n_ctx = 2048 llama_new_context_with_model: freq_base = 1000000.0 llama_new_context_with_model: freq_scale = 1 ggml_metal_init: allocating ggml_metal_init: found device: Apple M1 Pro ggml_metal_init: picking default device: Apple M1 Pro ggml_metal_init: default.metallib not found, loading from source ggml_metal_init: GGML_METAL_PATH_RESOURCES = /var/folders/r0/ww1scvgj7wz4dm_l3spst1gw0000gn/T/ollama1338032702 ggml_metal_init: loading '/var/folders/r0/ww1scvgj7wz4dm_l3spst1gw0000gn/T/ollama1338032702/ggml-metal.metal' ggml_metal_init: GPU name: Apple M1 Pro ggml_metal_init: GPU family: MTLGPUFamilyApple7 (1007) ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003) ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001) ggml_metal_init: simdgroup reduction support = true ggml_metal_init: simdgroup matrix mul. support = true ggml_metal_init: hasUnifiedMemory = true ggml_metal_init: recommendedMaxWorkingSetSize = 22906.50 MB
As they'd say in Renaissance Faire, "Huzzah!" [cue clinking of swords]
Should we use Apple Macs for LLM work?
I still don't really know enough to say, personally, that an Apple Silicon Mac would be a fast and productive if you were on the scientific end of LLMs, for example training models with fine tuning, LoRA, etc. There were some comments on bugs in PyTorch by one blogger, but I'm thinking that over time this stuff will get slowly corrected. That said, you can't run virtual machines on a Mac (same issue with the Mac Virtualization platform) and get accelerated GPU APIs expose to your programs, so if your project requires a virtual machine, you're stuck with a very expensive paperweight.
And before you think of doing this, the Apple Silicon Macs do NOT support Thunderbolt external GPUs. You have been warned.
Alternatives?
Maybe you could use a shared Linux workstation with a nice beefy card you'd access as a team via a VPN or something, so you can run training jobs etc. so you save some cost by sharing. I'm unsure whether it's worth it. That would be another up-front cost, and you'd have to maintain it.
Of course, as I mentioned in my last article you could you use a cloud provider (I happened to mention AWS because it's my goto) for your training and LLM work, but those costs vary and you will have to be very careful not to run up a big bill.
There are managed services / serverless engines that are beginning to surface, such as Amazon's suite of offerings around Bedrock and Kendra too, but these are going to be hard or impossible to develop on locally, you're tied to the cloud and the costs are incurred as you develop.
The Mac is fine for learning / basic development
But try to use the GPU if at all possible – the speed of CPU-only LLM processing is much slower than using Metal.
For writing code that runs queries on an LLM, against an already pre-trained model, a Mac with 32GB has 32GB of unified memory (that the GPU and CPU both share). If most of your work is integrating a RAG LLM solution, it could be good enough (albeit maybe slower than a really expensive GPU) to get work done as a developer, then push to a few engineers with beefier hardware or the cloud to shake it down.
In the end, we decided to have a native-mostly startup engine (running vite for the React front-end, Uvicorn in Python for our RESTful BFF server, Ollama natively, and virtualizing our Postgres engine with pgvector, as a developer launch option.
In the cloud, the docker-compose file works great, as long as you add in the proper NVIDIA detection settings (checkout the deploy config for the ollama engine:)
ollama:
container_name: ollama
image: ollama/ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
Yep, with NVIDIA on Linux (or Windows WSL2 and Docker Desktop) you even have to activate the GPU in the Docker container with configuration! So configurer beware.
It's a moving landscape
Things are changing constantly. New APIs are coming out all the time, and if you wait 6 months, this article may be completely irrelevant. Just consider that, as of Feb 22, 2024, this is the way it is: don't virtualize Ollama in Docker, or any (supported) Apple Silicon-enabled processes on a Mac. For other GPU-based workloads, make sure whether there is a way to run under Apple Silicon (for example, there is support for PyTorch on Apple Silicon GPUs, but you have to set it up properly.